(扬州大学,江苏扬州)
摘要:图像分类是计算机视觉领域的一个重要的任务,为了解决这一任务,本文提出一种基于每一类的判别信息生成的字典模型,称为监督的类判别的字典学习(Supervised Class-discriminant Dictionary Learning, SCDDL)模型。SCDDL模型从训练集中学习得到一个字典和在这字典上的表示系数,不仅不同类别的字典对训练样本的重建误差具有判别性而且表示系数具有判别性。在此基础上,充分利用重建误差的判别性和表示系数的判别性提出相应的图像分类方案。大量的实验结果表明,与现有的模型分类方法相比较,该分类方法在图像分类的任务上具有较好的分类性能,且算法的效率高。
关键词:字典学习;图像分类;协同表示;有监督学习。
Supervised Class-Discriminant Dictionary Learning Algorithm based on Cooperative Representation
Zhang Jie
(Yangzhou University, Jiangsu, 225009, China)
Abstract: Image classification is an important task in the field of computer vision. To solve this task, this paper proposes a Dictionary model called Supervised Class-discriminant Dictionary Learning (SCDDL) model.SCDDL model obtains a dictionary learning from the training set and the representation coefficients on the dictionary, which are discriminative not only for different class of dictionaries but also for the representation coefficients.On this basis, the discriminability of reconstruction error and representation coefficient is fully utilized to propose the corresponding image classification scheme.A large number of experimental results show that, compared with the existing model classification methods, this classification method has better performance in image classification task, and the efficiency of the algorithm is high.
Key words: Dictionary learning; Image classification; Collaborative representation.
一、引言
近年来稀疏表示编码[1]取得了较好的应用,比如在表示自然的图像上。图像可以表示为一组基的线性组合的形式,其中线性组合的表示系数是稀疏的。基于稀疏表示的分类模型(Sparse Representation based Classification, SRC)[2]在人脸识别上取得了很好的效果,SRC算法的思想是:同类别的样本可以由本类中的其他样本的线性组合表示,因此字典直接由训练样本组成,字典的原子就是训练样本。然后在稀疏表示的约束下(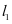 范数约束)对测试样本进行稀疏编码,因此测试样本可以看成是字典原子的稀疏线性组合。SRC分类器的设计依据的方法是最小重建误差准则。Zhang Lei等人认为SRC算法的成功采用的是协同表示而不是稀疏表示[3],并且提出了基于协同表示的分类(Collaborative representation based classification CRC)算法,在稀疏编码的时候加上了
范数约束)对测试样本进行稀疏编码,因此测试样本可以看成是字典原子的稀疏线性组合。SRC分类器的设计依据的方法是最小重建误差准则。Zhang Lei等人认为SRC算法的成功采用的是协同表示而不是稀疏表示[3],并且提出了基于协同表示的分类(Collaborative representation based classification CRC)算法,在稀疏编码的时候加上了 范数的正则项约束。实验结果表明,CRC算法比SRC算法的分类正确率更高,并且CRC算法的计算复杂度更低[3]。
范数的正则项约束。实验结果表明,CRC算法比SRC算法的分类正确率更高,并且CRC算法的计算复杂度更低[3]。
SRC算法和CRC算法利用原始训练集直接构建字典,然后对测试样本进行稀疏编码。在图片分类任务上,SRC算法和CRC算法在图像分类的任务上并不是很高效。因此,越来越多学者致力于学习得到一个更好的字典,并能很好的对测试样本进行稀疏表示。在学术界中,一个经典的字典学习算法K-均值奇异值分解(K-SDV)算法[5],该算法致力于从训练集中高效的学习到一个过完备字典并用于对图像的重建和图像的压缩,但并不是很适合于图像的分类任务。在K-SDV算法提出之后,Julien Mairal等人[6]改进K-SDV算法,提出了用于图像分割和场景分析的DKSVD算法。Jiang Zhuolin等人[17]对K-SDV算法改进,提出了标签一致性K-SDV(LC-KSDV)算法,该算法在K-SDV的目标函数中加入标签一致正则项,使得稀释编码更具判别性,从而使得该算法在图像的分类上有不错的表现。近年来,Yang Meng等人[13]提出基于Fishe线性判别(Fisher Discrimination Dictionary Learning FDDL)算法在图像的分类任务上取得了较好的效果。然而,如何设计出一个出色的判别字典学习算法,使得该字典能够很好的表示和对未知样本进行分类,在该问题上仍然是值得研究的。
在本次研究中,设计出一个新的判别字典学习算法——监督的类判别字典学习(SCDDL)算法。该算法学习得到的字典具有类别信息,字典中的原子和类别的标签相对应。同一类别的字典和表示系数能够很好重建本类别的训练样本。不同类别的字典和表示系数重建训练样本能力较弱,此外,不同类别的表示系数具有较大的差异性。因此,对于一个测试样本,可以充分利用上述的两种信息实现分类。在图像的分类任务中,与已有的其他实验数据相比SCDDL模型相比于其他字典学习模型相比较具有较高的分类正确率。
二、监督的类判别字典学习
我们提出了一个能够从带有标签的训练样本中学习得到一个具有判别信息字典的学习算法,称作监督的类判别字典学习。给定带有标签的训练集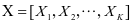 ,训练集中总共有
,训练集中总共有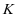 个类别,
个类别,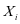 是第
是第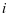 个类别的训练集。用
个类别的训练集。用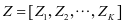 作为表示系数,我们想要得到的结果是字典
作为表示系数,我们想要得到的结果是字典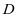 经过系数表示后能够很好的表示训练样本,即
经过系数表示后能够很好的表示训练样本,即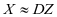 。在这基础上我们还希望字典
。在这基础上我们还希望字典 和系数
和系数 在不同的类别之间具有很好的判别性,也就是说字典
在不同的类别之间具有很好的判别性,也就是说字典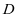 和系数
和系数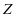 要和类别标签相关联。为了解决上述目标,我提出了以下的模型:
要和类别标签相关联。为了解决上述目标,我提出了以下的模型:
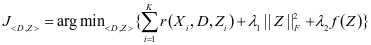
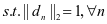 (2-1)
(2-1)
公式(2-1)中的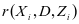 是表示约束项(Representation Constrained Term) [7],
是表示约束项(Representation Constrained Term) [7],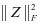 是不同于FDDL模型[13]中的的系数约束项,
是不同于FDDL模型[13]中的的系数约束项,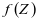 是系数判别项,
是系数判别项,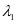 和
和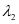 是常数系数。SCDDL模型中使用
是常数系数。SCDDL模型中使用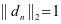 作为限制条件,保证原子都是单位的,因此字典原子可视为一组单位基。下面将说明 和 中的细节和他们在模型中的作用。
作为限制条件,保证原子都是单位的,因此字典原子可视为一组单位基。下面将说明 和 中的细节和他们在模型中的作用。
我们可以用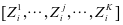 的形式来表示
的形式来表示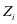 ,即得到等式
,即得到等式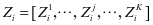 。其中
。其中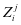 是第
是第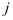 类子字典
类子字典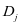 关于第
关于第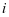 类样本
类样本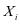 的表示系数。我们希望的是
的表示系数。我们希望的是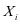 很够很好的被
很够很好的被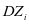 表示,即
表示,即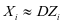
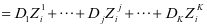 。所以,用
。所以,用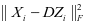 对样本
对样本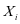 重建,考虑子字典
重建,考虑子字典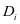 是和第
是和第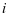 类样本相关联,但是我们不希望第 ,
类样本相关联,但是我们不希望第 ,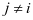 ,类的字典能够很好的对样本 重建,所以我们使
,类的字典能够很好的对样本 重建,所以我们使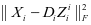 和
和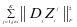 这两项最小化以达到目的。因此,表示约束项
这两项最小化以达到目的。因此,表示约束项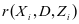 [14]被定义为如下的式子:
[14]被定义为如下的式子:
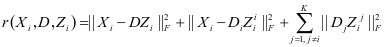 (2-2)
(2-2)
下面将说明公式(2-2)中的每一项在整个式子中的作用。
第1种情况,当有 = 时,虽然字典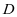 和系数
和系数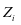 能够对第
能够对第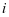 类训练本 很好的表示,但是第 类字典
类训练本 很好的表示,但是第 类字典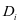 和系数
和系数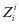 并不能很好的对训练样本 重建,如图2-1中的(a)所示, 和
并不能很好的对训练样本 重建,如图2-1中的(a)所示, 和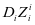 的可视化图相差甚远。并且,第
的可视化图相差甚远。并且,第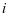 类系数 在系数 中不能有很好的判别性, 不能和
类系数 在系数 中不能有很好的判别性, 不能和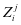 ,
,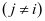 ,形成很好的区别,如图2-2中的(a)所示。
,形成很好的区别,如图2-2中的(a)所示。
第二种情况,当 = +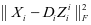 ,我们使第
,我们使第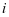 类的字典
类的字典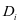 与第 类系数 能够对样本 很好的重建,如图2-1中的(b)所示, 和 的相似性较高。同时第 类系数 在系数 中有较好的判别性,如图2-2中的(b)所示。
与第 类系数 能够对样本 很好的重建,如图2-1中的(b)所示, 和 的相似性较高。同时第 类系数 在系数 中有较好的判别性,如图2-2中的(b)所示。
第三种情况,当 = + +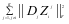 时,当我们对第 类样本重建时,尽量减少第 类字典
时,当我们对第 类样本重建时,尽量减少第 类字典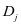 和
和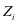 系数中的第 类系数 对重建结果的影响。从图2-1中的(c)看得出, 和 的相似性很高,因此 能够很好的对第 类训练样本 重建。并且在上一步的工作基础上 的判别性进一步增强, 和 , ,形成很好的区别。
系数中的第 类系数 对重建结果的影响。从图2-1中的(c)看得出, 和 的相似性很高,因此 能够很好的对第 类训练样本 重建。并且在上一步的工作基础上 的判别性进一步增强, 和 , ,形成很好的区别。
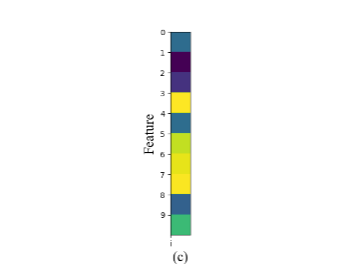
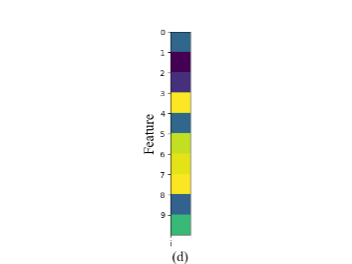
图2-1第 训练样本
训练样本 和
和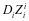 对训练样本重建,(a)为训练样本 ,(b)、(c)、(d)分别为第一、二、三种情况下 对训练样本 的重建
对训练样本重建,(a)为训练样本 ,(b)、(c)、(d)分别为第一、二、三种情况下 对训练样本 的重建
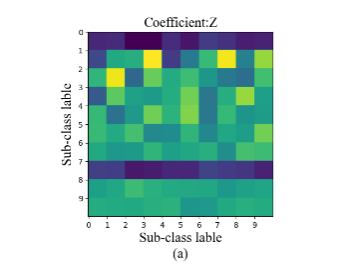
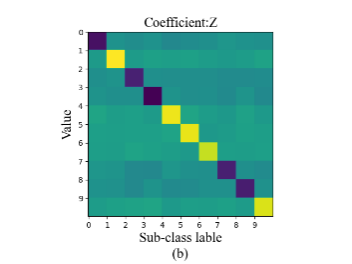
图2-2稀疏表示系数,(b)、(c)、(d)分别为第一、二、三种情况下的稀释表示系数矩阵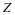
稀疏表示SRC的本质就是样本尽可能的被表示为字典原子的线性组合形式[2],稀疏性是指系数在表示同类别样本时该类别的系数具有较大的分量,不同类别的系数具有较小的分量。同样的,我们使SCDDL模型的系数矩阵更加贴合与SRC的思想,我们增加系数区别项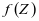 。理论上,如果
。理论上,如果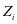 和
和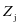 是属于同一类的标签,
是属于同一类的标签,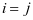 ,那么
,那么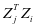 的值就会很大,如果属于不同的类别标签,
的值就会很大,如果属于不同的类别标签,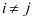 ,那么值 就会很小,因此文本定义系数区别项如下:
,那么值 就会很小,因此文本定义系数区别项如下:
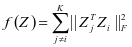 (2-3)
(2-3)
在这一项下, 中的其他类别表示系数 , ,就会变得较小,因此,进一步增强了表示系数矩阵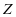 的判别性。同时,在第
的判别性。同时,在第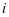 类训练集重建误差 具有更小的值,而
类训练集重建误差 具有更小的值,而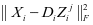 具有较大的值,因此也增强了重建误差的判别性。
具有较大的值,因此也增强了重建误差的判别性。
通过将公式2-2和公式2-3代入公式2-1,可以得到本文的完整模型:
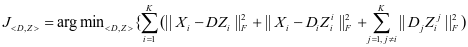
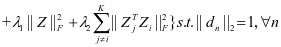 (2-4)
(2-4)
在本模型中,通过学习得到的字典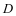 和稀疏表示系数
和稀疏表示系数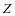 ,能够使得
,能够使得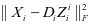 具有较小的值而
具有较小的值而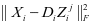 , ,具有较大的值。因此,第
, ,具有较大的值。因此,第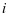 类的字典
类的字典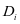 对于同类的样本
对于同类的样本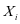 有较小的重建误差,对于不同类的样本
有较小的重建误差,对于不同类的样本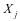 , ,据有较大的重建误差,所以我们认为重建误差具有判别性。不仅如此,第 类的样本在 上的表示系数 相对于在
, ,据有较大的重建误差,所以我们认为重建误差具有判别性。不仅如此,第 类的样本在 上的表示系数 相对于在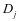 上的表示系数
上的表示系数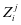 有较强的差异性。因此,我们说表示系数
有较强的差异性。因此,我们说表示系数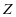 有判别性。
有判别性。
三、模型的求解
公式2-4的的目标函数中有两个未知的变量 和 ,我们采用的方法是固定其中一个变量求解另一个变量,固定字典 ,求解系数 ;固定系数 ,求解字典 ,进行迭代求解。同时当固定一个变量时,目标函数中只有一个未知变量。此时,目标函数就成了凸函数[15],可运用凸优化问题求解。求解的算法见如下步骤。
我们固定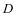 ,假定 是已知的,目标函数就变成了求解系数矩阵
,假定 是已知的,目标函数就变成了求解系数矩阵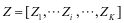 ,依次求解
,依次求解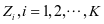 。当求解
。当求解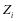 时,假设
时,假设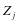 是已知的。所以目标函数(2-4)变成了求解下面的式子:
是已知的。所以目标函数(2-4)变成了求解下面的式子:
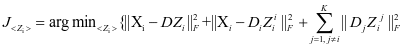
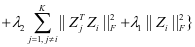 (3-1)
(3-1)
由于存在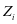 的分量 和 ,我们使用投影矩阵
的分量 和 ,我们使用投影矩阵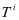 和
和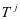 使得等式
使得等式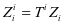 和
和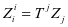 成立,因此我们使用
成立,因此我们使用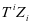 和
和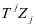 替换 和 。投影矩阵 ( )的作用是使
替换 和 。投影矩阵 ( )的作用是使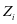 (
(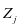 )关于第
)关于第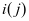 类保持不变,其他的分量变为
类保持不变,其他的分量变为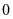 。通过求解上面的等式得到如下的结果:
。通过求解上面的等式得到如下的结果:
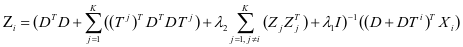 (3-2)
(3-2)
固定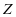 ,假定
,假定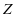 已知,目标函数变为了求解字典
已知,目标函数变为了求解字典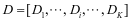 。我们依次的更新,当求解
。我们依次的更新,当求解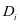 时,假定
时,假定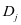 (
(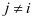 )是已知的。所以求解的问题就变成了如下的等式:
)是已知的。所以求解的问题就变成了如下的等式:
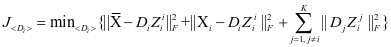
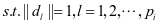 (3-3)
(3-3)
式中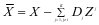 ;
;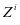 是训练集
是训练集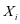 在字典
在字典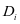 上的表示系数。公式3-2还可以按照文献[14]的方法进一步简化成如下的形式:
上的表示系数。公式3-2还可以按照文献[14]的方法进一步简化成如下的形式:
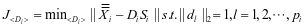 (3-4)
(3-4)
式中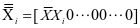 ,
,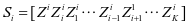 。这里可以采用Yang Meng等人的方法逐个求解字
。这里可以采用Yang Meng等人的方法逐个求解字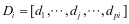 中的原子[8]。当求解
中的原子[8]。当求解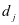 时,假定
时,假定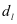
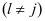 已知,直到更新完该类的中的全部全部原子。求解 的式子可以描述为:
已知,直到更新完该类的中的全部全部原子。求解 的式子可以描述为:
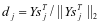 (3-5)
(3-5)
其中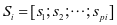 ,
,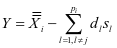 。
。
下面给出SCDDL模型求解的具体算法。
SCDDL模型求解算法 |
初始化迭代次数 2、While目标优化函数2-4未收敛且未达到最大迭代次数do 3、固定字典 4、固定系数 5、迭代次数加1: 6、End while 7、输出 |
四、分类的方案
通过SCDDL模型学习得到的字典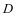 和
和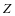 后,其中不同类别的字典对于训练样本的重建误差具有判别性。同时不同类别的表示系数具有判别性。本文充分利用上述的两种判别信息提出以下的分类的方案。
后,其中不同类别的字典对于训练样本的重建误差具有判别性。同时不同类别的表示系数具有判别性。本文充分利用上述的两种判别信息提出以下的分类的方案。
当样本测试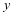 给定时,我们可以利用CRC模型[8]中的
给定时,我们可以利用CRC模型[8]中的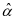 作为样本 在字典 的表示系数,
作为样本 在字典 的表示系数,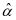 定义为如下:
定义为如下:
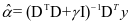 (4-1)
(4-1)
其中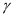 是一个常数,
是一个常数,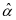 表示为
表示为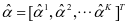 。其中
。其中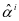 为测试样本在子字典
为测试样本在子字典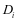 上的表示系数。我们首先利用重建误差的判别性对样本分类,如果 是来自第
上的表示系数。我们首先利用重建误差的判别性对样本分类,如果 是来自第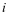 类的样本,则
类的样本,则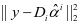 具有较小的值,而
具有较小的值,而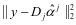 ,
,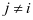 ,具有较大的值。其次还可以利用系数表示矩阵的判别性进行分类,
,具有较大的值。其次还可以利用系数表示矩阵的判别性进行分类,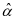 是 在字 上的表示系数,如果 是来自第 类的样本,那么
是 在字 上的表示系数,如果 是来自第 类的样本,那么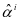 和 很接近而 和。结合重建误差和表示系数的判别性,本文提出的分类方案如下:
和 很接近而 和。结合重建误差和表示系数的判别性,本文提出的分类方案如下:
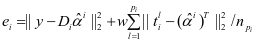 (4-2)
(4-2)
式中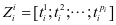 ,
,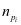 为第
为第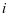 类字典原子的个数,
类字典原子的个数,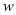 是权值,用于衡量
是权值,用于衡量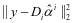 和
和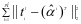 对分类的影响比重。分类规则可以定义为如下:
对分类的影响比重。分类规则可以定义为如下:
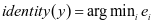 。 (4-3)
。 (4-3)
五、实验结果及分析
本节评价SCDDL模型和分类方案在图像分类任务上的性能。下面分别说明实验使用的数据、实验的参数设置、实验结果以及和其他主流字典学习算法做对比。
 这部分我们来评估SCDDL模型在Extended Yale B [10]人脸数据集上的效果。采用经过裁剪成192×168像素的标准图像,裁剪后人脸数据只保留脸部特征。本文用含有10个个体的640张人脸图像,每个个体有64张不同灰度的人脸图像。从每个个体中随机选取32张人脸图像作为训练集,其余的32张人脸图像作为测试集。图5-1给出了某个个体的8张人脸图像样例图。
这部分我们来评估SCDDL模型在Extended Yale B [10]人脸数据集上的效果。采用经过裁剪成192×168像素的标准图像,裁剪后人脸数据只保留脸部特征。本文用含有10个个体的640张人脸图像,每个个体有64张不同灰度的人脸图像。从每个个体中随机选取32张人脸图像作为训练集,其余的32张人脸图像作为测试集。图5-1给出了某个个体的8张人脸图像样例图。
图5-1 Extended Yale B 数据集的样例图片
如不进行特别的说明,本文默认用如下的参数文用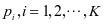 表示SCDDL模型中一类子字典
表示SCDDL模型中一类子字典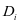 原子的个数。由于实验采用的每一类训练集
原子的个数。由于实验采用的每一类训练集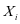 的样本数相同且为32个,所以设置每一类字典的原子数
的样本数相同且为32个,所以设置每一类字典的原子数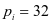 。在公式2-1中的
。在公式2-1中的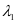 和
和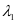 ,分别设置
,分别设置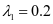 和
和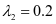 。在分类的方案中的公式4-1和4-2分别有
。在分类的方案中的公式4-1和4-2分别有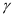 和
和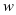 两个参数,我们设置
两个参数,我们设置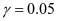 和
和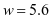 。
。
SCDDL模型在Extended Yale B人脸数据集上表现处了良好的分类性能精度达到了98.8%,在此说明,分类的精度和模型、数据集及参数有关。下表给出各种优秀的字典学习算法在Extended Yale B人脸数据集的分类结果。
表 5-2 Extended Yale B人脸数据集字典学习算法结果对比
模型 正确率 | 模型 正确率 |
SRC[2] 90.0 SVM 88.8 DKSVD[12] 75.3 LC-KSVD[29] 90.6 | DLSI[16] 91.4 DLSI*[16] 94.1 FDDL[13] 96.7 SCDDL 98.8 |
从表5-2可以看出SCDDL模型在Extended Yale B人脸数据集上的分类正确率最高,其次就是FDDL模型。
由于本文的SCDDL模型在更新系数矩阵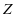 上使用的求解算法不同于FDDL模型,FDDL模型采用的是传统的梯度下降法,而SCDDL模型直接求解出公式3-1得极小值。同时,优化目标函数公式2-1存在下界[15],在SCDDL模型求解算法下,每迭代一次目标函数的值就会相应的减少,在Extended Yale B数据下实验目标函数到达最大的迭代次数,且函数值趋向于一个稳定的值,下图可以看到迭代求解次数和目标优化函数值的关系
上使用的求解算法不同于FDDL模型,FDDL模型采用的是传统的梯度下降法,而SCDDL模型直接求解出公式3-1得极小值。同时,优化目标函数公式2-1存在下界[15],在SCDDL模型求解算法下,每迭代一次目标函数的值就会相应的减少,在Extended Yale B数据下实验目标函数到达最大的迭代次数,且函数值趋向于一个稳定的值,下图可以看到迭代求解次数和目标优化函数值的关系
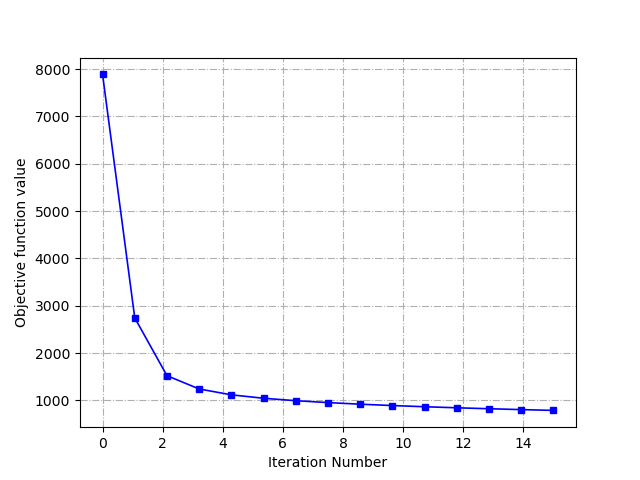 图5-3 SCDDL模型求解目标函数值的变换过程
图5-3 SCDDL模型求解目标函数值的变换过程
从图5-3可以看出当迭代次数到达4次时目标函数的值就基本达到稳定的值了,所以此算法较为高效。
【参考文献】
[1]李子奇. 基于稀疏表示的图像分类算法研究[D].江南大学,2020.
[2]Wright John; Yang A Y, Ganesh Arvind, Sastry S S, Ma Yi, Robust Face Recognition via Sparse Representation[j]. IEEE Transactions on Pattern Analysis and Machine Intelligence: 2009,31(2): 210-227.
[3]Zhang Lei, Yang Meng, Feng Xiangchu.Sparse representation or collaborative representation: Which helps face recognition?[C]// Barcelona. International Conference on Computer Vision. IEEE, 2011:471-478.
[5] M.Aharon, M.Elad and A. Bruckstein, K-SVD: An algorithm for designing overcomplete dictionaries forsparse representation[J]. IEEE Transactions on Signal Processing:2006,54(11):4311-4322.
[6]Julien Mairal, Francis Bach, Jean Ponce, Guillermo Sapiro, and Andrew Zisserman, Discriminative learned dictionaries for local image analysis[C]//Anchorage,AK. 2008 IEEE Conference on Computer Vision and Pattern Recognition,IEEE 2008:1-8.
[7] Meng Yang, Lei Zhang, Xiangchu Feng, and David Zhang.Sparse representation based ?sher discrimination dictionary learning for image classi?[J].International Journal of Computer Vision:2014.109(3):209-232.
[9]Taneja Shweta,Gupta Charu, Aggarwal Sakshi, Jindal Veni. MFZ-KNN — A modified fuzzy based K nearest neighbor algorithm: Noida. 7100689[P].2015.
[10] Lee K C, Ho Jeffrey, Kriegman D J, Acquiring linear subspaces for face recognition under variable lighting. Pattern Analysis and Machine Intelligence: 2005, 27(5): 684-698.
[12] Zhang Qiang, Li Baoxin. Discriminative K-SVD for dictionary learning in face recognition[C]// San Francisco, CA. 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, IEEE, 2010:2691–2698.
[13]Yang Meng, Zhang Lei, Feng Xiangchu, Zhang David. Discrimination Dictionary Learning for sparse representation[C]// Barcelona. 2011 International Conference on Computer Vision, Barcelona,IEEE 2011:543-550
[14] Yang, Meng, Zhang, Lei, Feng, Xiangchu, Zhang, David. Sparse representation based fisher discriminationdictionary learning for image classification[J]. International Journal of Computer Vision,2014, 109(3):209–232。
[15]杨宝庆. 基于字典学习的图像分类算法及应用研究[D].上海交通大学,2017.
[16] Ignacio Ramirez, Pablo Sprechmann, Guillermo Sapiro. Classification and clustering via dictionary learning with structured incoherence and shared features[C]// San Francisco,CA. 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.IEEE,2010:3501–3508.
[17]Jiang Zhuolin, Lin Zhe, Davis L S. Label consistent K-SVD: Learning a discriminative dictionaryfor recognition[J]. Pattern Analysis and Machine Intelligence: 2013, 35(11):2651–2664.
【基金项目】
扬州大学大学生创新创业训练计划项目(学术科技创新基金项目)
【作者简介】
张捷(1997-),男,汉族,广西贵港市人,扬州大学,本科学历

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网 琼ICP备2021005105号



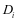 的原子为样本
的原子为样本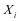 的特征向量,
的特征向量,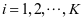 。初始化
。初始化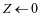 。
。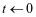 。
。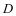 ,按照公式3-2更新每一类系数
,按照公式3-2更新每一类系数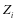 ,
,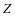 ,按照公式3-5更新每一类字典
,按照公式3-5更新每一类字典