江南机电设计研究所,贵州 贵阳, 550006
摘要:在语音通信过程中往往都混有各种噪声,为降低噪声的干扰,提高语音质量和可懂度,本文提出了一种基于压缩感知(Compressed Sensing, CS)的语音降噪算法研究。首先利用语音端点检测方法判断出语音段和非语音段,去除非语音段的噪声,然后利用语音和噪声在离散余弦变换(Discrete Cosine Transform, DCT)域具有不同的稀疏特性以及正交匹配追踪(Orthogonal Matching Pursuit, OMP)重建算法所采用的相似度特性实现对带噪语音段的噪声滤除。仿真结果表明,与经典子空间语音降噪算法相比,本文提出的算法去噪效果更好。
主题词:压缩感知;语音端点检测;语音降噪算法
1 引言
CS是一种信号信息提取与恢复的过程,在采样过程中利用较少的数据有效提取信号信息,然后通过重建算法从采样信息中恢复原信号。语音增强过程是指对带噪语音信号进行处理,消除或者降低噪声的干扰,恢复出原来纯净的语音信号,所以,CS过程与语音增强的本质是类似的。因此,可以利用语音信号与干扰噪声在压缩过程中的不同特性,实现语音增强。
2压缩感知理论
CS利用输入信号之间相关性和特有的稀疏特性,通过观测矩阵对数据进行投影,得到一些非自适应线性预测值,最后从这些相对较小的观测值中精确恢复出原始信号。
2.1 信号的稀疏表示
一个长度为![]() 的离散信号
的离散信号![]() ,是一个
,是一个![]() 维列向量,
维列向量,![]() 。这个信号可以用一个正交稀疏基
。这个信号可以用一个正交稀疏基![]() 来描述。
来描述。
![]() (2-1)
(2-1)
式(2-1)中![]() 是
是![]() 的一组系数序列,
的一组系数序列,![]() ,只有当
,只有当![]() 中存在K(K 才可以被压缩和进行稀疏表示,其稀疏度为
中存在K(K 才可以被压缩和进行稀疏表示,其稀疏度为![]() 。
。
2.2 信号的测量
一个可压缩信号可以被认为是包含少量数据的,将这些有用信息用非自适应的线性预测值进行提取。
![]() (2-2)
(2-2)
式(2-2)中![]() 是对信号
是对信号![]() 进行观测后得到的一个
进行观测后得到的一个![]() 维列向量,
维列向量,![]() 是一个固定和独立的
是一个固定和独立的![]() 维矩阵,不依赖于信号
维矩阵,不依赖于信号![]() 。因为
。因为![]() ,因此从观测向量
,因此从观测向量![]() 中恢复出原始信号
中恢复出原始信号![]() 似乎是不可能的。但是基于CS理论的框架以及信号
似乎是不可能的。但是基于CS理论的框架以及信号![]() 是
是![]() 稀疏的前提下,当传感矩阵
稀疏的前提下,当传感矩阵![]() 遵守约束等距性质(RIP)或者观测矩阵
遵守约束等距性质(RIP)或者观测矩阵![]() 与稀疏基
与稀疏基![]() 具有非相干性,那么信号就是有可能成功恢复的。
具有非相干性,那么信号就是有可能成功恢复的。
2.3 信号的重构
将一个稀疏或可压缩信号从一个小的投影集中恢复出来,有两个原则必须满足:信号的稀疏性和感知方式的非相干性。
对于一个可压缩信号来说,只要能找到一个稀疏基进行表示,就能得到该信号的稀疏表示,因此如果传感矩阵满足RIP准则或者![]() 与
与![]() 是不相干的,那么可以通过求解最小1范数问题进行信号重构算法。具体恢复过程如式(2-3):
是不相干的,那么可以通过求解最小1范数问题进行信号重构算法。具体恢复过程如式(2-3):
![]() (2-3)
(2-3)
3 语音端点检测
3.1 基本概念
本文利用语音段和非语音段的特点设计语音端点检测方法,该方法能够检测出一段语音信号中的所有语音段和静音段。
3.2 语音功率估计
设![]() 语言信号,进行加窗分帧,帧长为
语言信号,进行加窗分帧,帧长为![]() 。
。![]() 为其第
为其第![]() 帧,
帧,![]() 是相应的傅里叶变换结果,第
是相应的傅里叶变换结果,第![]() 帧的语音功率估计值为
帧的语音功率估计值为![]() :
:
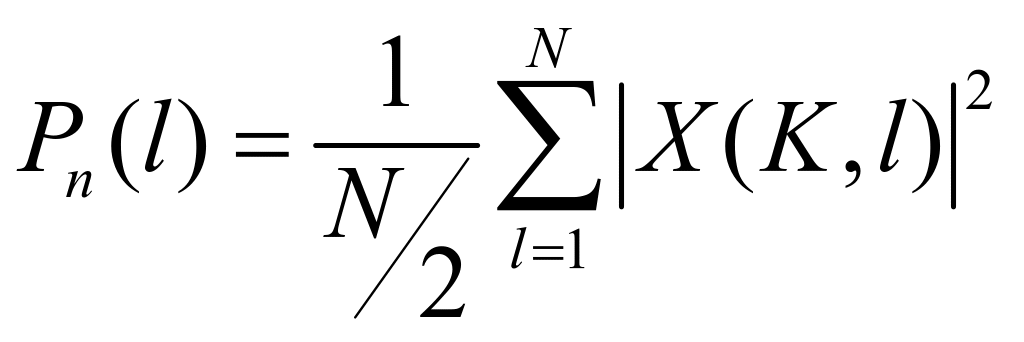 (3-1)
(3-1)
3.3 噪声功率估计
认为语音信号的初始段为噪声段,可通过取前![]() 帧信号的噪声功率谱对语音噪声功率进行估计,该语音信号的噪声功率值
帧信号的噪声功率谱对语音噪声功率进行估计,该语音信号的噪声功率值![]() 计算如下:
计算如下:
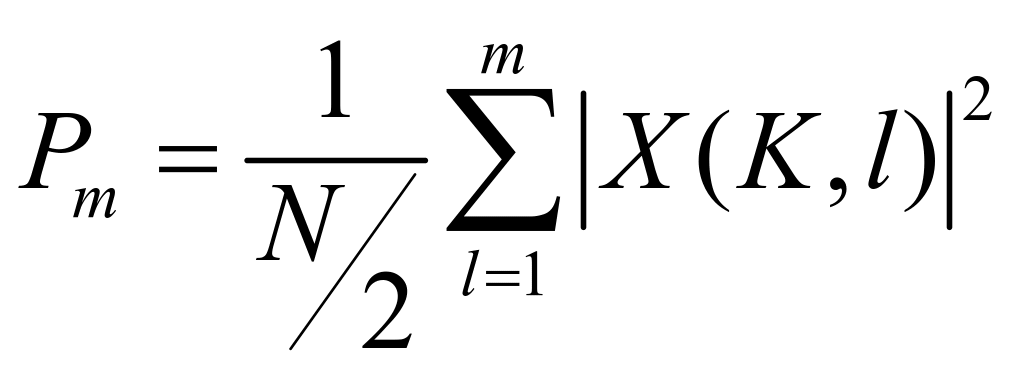 (3-2)
(3-2)
![]() (3-3)
(3-3)
本文中![]() 取值5。
取值5。
3.4 纯净语音功率估计
将公式(1)计算的语音功率估计值与公式(3)计算的噪声功率估计值相减,得到纯净语音功率值![]() ,计算如下:
,计算如下:
![]() (3-4)
(3-4)
3.5 语音段划分
为验证该端点检测方法的有效性,通过对语音信号加不同信噪比的白噪声环境下进行实验,结果表明,即使是在较低的信噪比下,该方法仍能够比较准确地检测出语音的起止端点。
4 语音增强
基于CS语音降噪算法框图如图1所示。
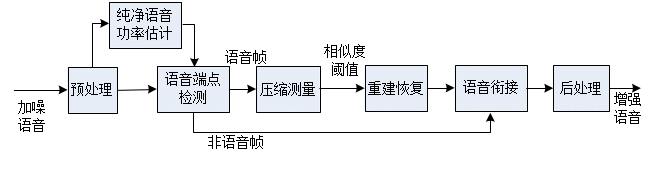 图1 CS算法实现语音增强框图
图1 CS算法实现语音增强框图
a)对含噪语音进行预处理。预处理先对语音信号进行分帧,设置合适的帧长:如果帧长选择太长,信号维数N则比较大,利用OMP算法计算所需的时间较长;帧长太短,则不足以区分语音信号和噪声信号,去噪效果不好。所以,设置较小的帧移量,可以提高去噪效果;
b)进行纯净语音功率估计,并对信号进行语音端点检测,识别出语音段和非语音段。若为非语音段,进行衰减后跳到e)条执行,否则继续;
c)利用高斯随机测量矩阵对含噪语音进行压缩测量。观测维数M应该在保证包含语音信息的前提下尽可能的小,缩短处理时间;
d)设置相似度迭代阈值,利用改进的OMP算法重建语音信号;
e)将恢复得到的当前语音帧与前一帧语音衔接,重叠部分进行平均,得到最后增强结果。
5 仿真实验
实验语音信号来自NOIZEUS语音库[4],该库是专门设计用于评价语音降噪算法性能的数据库。库中包含30条句子(由三男和三女朗诵)。数据库中语音采样频率为8kHz。由于NOIZEUS噪声语音库不包含白噪声,实验中采用高斯分布随机白噪声干扰纯净语音,以产生不同信噪比的带噪语音,并利用两种增强算法进行增强处理,对比分析增强效果。如图2~图3所示。
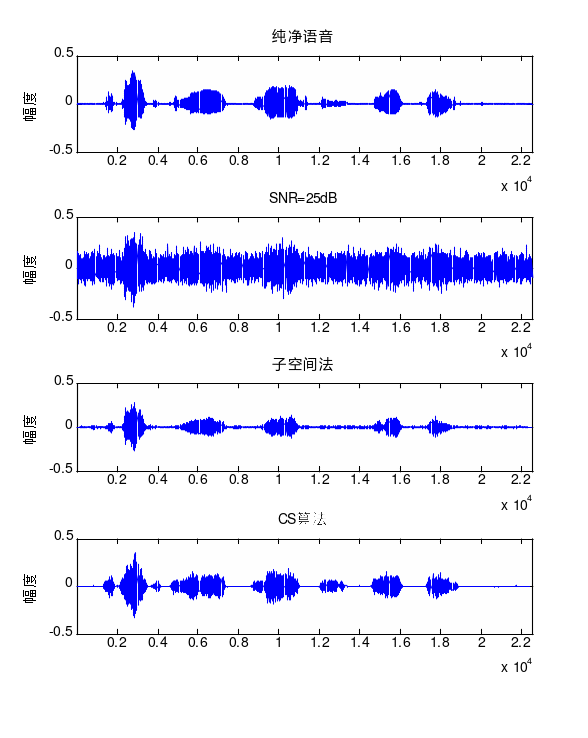
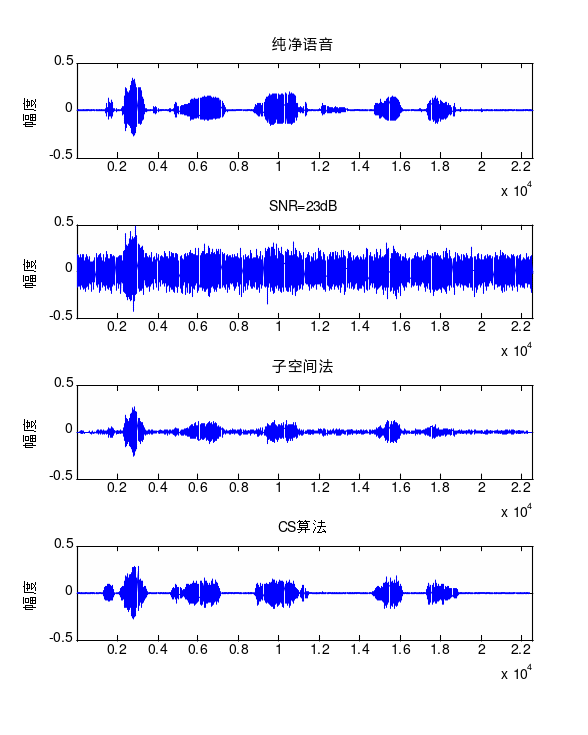
图2 语音增强(SNR=25dB) 图3 语音增强(SNR=23dB)
如图所示,SNR=25dB和SNR=23dB时,信号受噪声干扰较大,此时本文算法比子空间法对语音的增强效果好。
6 结束语
本文设计一种基于功率谱估计的语音检测方法,识别出语音段和非语音段,减少对语音信号的处理时间。在此基础上,提出一种基于CS的语音降噪算法,利用语音和噪声信号在DCT域的不同稀疏性以及CS的重构算法的特性对带噪语音中纯净语音进行提取,实现对语音信号的去噪处理。实验证明,相比经典的子空间语音降噪算法,本文提出的算法能够在低信噪比环境下,较小失真的还原语音信号。
参考文献:
[1] Candes E J,Wakin M B.An introduction to compressive sampling[J].Signal Processing Magaine,2008,25(2):21-30.
[2] Donoho D L.Compressed sensing[J].Information Theory,IEEE Transactions on,2006,52(4):1289-1306.
[3] Candes E J,Tao T.Near-optimal signal recovery from random projections:Universal encoding strategies[J].Information Theory,IEEE Transactions on,2006,52(12):5406-5425.
[4] Hu Y, Philipos C Loizou. Subjective comparison and evaluation of speech enhancement algorithms[J].Speech Communication, 2007, 49(7-8): 588-601.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网 琼ICP备2021005105号



