摘要:本文论述了一种基于视觉动作识别的人-车交互系统的基本技术方案,包含车身控制模块(BCM)、车内摄像头、车内传感器、视觉识别模块、视觉识别系统、车内信号传输网络、汽车T-BOX、车载电子设备、车联网APP模块,及其完成人机交互的结构、原理。
关键词: 视觉识别、人机交互、手势识别
随着汽车电子技术的发展,大量的车载电子设备应用于汽车,包括汽车仪表、自动空调、车载触屏等,而智能网联技术的发展,车机的功能越来越丰富,手机的各种APP,例如微信、QQ音乐、喜马拉雅等,都可以通过投屏到车机屏幕使用,驾驶人、乘客与车机的交互越来越来,而未来随着5G技术、自动驾驶技术的发展,汽车更将会逐渐成为一个移动办公、娱乐平台,这样对人-车之间的信息交互提出了更高、更多的要求。
传统的汽车,主要通过机械电子开关或电子触屏进行控制车内电子设备,实现播放停止音乐、开关空调等功能,目前智能网联汽车中,人-车使用语音交互越来越多,但语音也存在着识别率不够高、需频繁唤醒等问题,且在需要安静环境时不适合用语音交互。在人与人沟通中,手势、肢体语言包含了大量信息,数据统计在沟通中手势动作能起到55%的作用,所以手势、肢体动作识别可作为车辆中人-机交互中除语言外的重要补充手段。
目前已有的车辆手势识别技术主要是靠红外手势识别芯片采集信号至汽车MCU,处理后转化成对汽车的控制指令。由于红外感应传感器本身的技术特点,存在感应距离小、可识别内容少、识别内容不易升级、且在环境温度与人体温度接近时识别率低的问题。
随着摄像头技术(广角、清晰度提升)的发展与图片识别算法的不断成熟,使得基于视觉、图像识别的手势识别技术得以在汽车上应用,且具备识别范围广、不受限于环境温度、可识别内容多、识别系统易升级的特点。本文提出一种基于视觉动作识别的人-车交互系统,采用摄像头、视觉图像识别技术及相应算法解决现有车辆红外手势识别,主要靠红外手势识别芯片采集信号至汽车MCU,存在识别范围窄、识别内容少,识别内容不易升级、环境温度高时识别率低的问题。
该交互系统的核心为视觉识别系统,下面首先介绍视觉识别系统的结构。视觉识别系统硬件结构包含:车内摄像头、车内传感器、视觉识别模块、车机、BCM等模块。
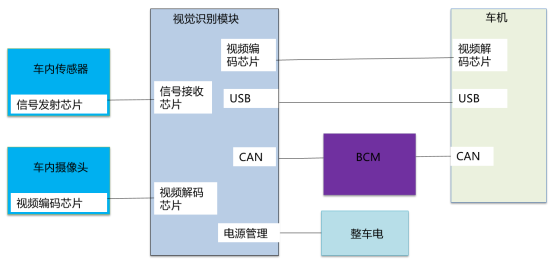
图1 车内视觉识别系统硬件结构
整个交互系统包含车身控制模块(BCM)、车内摄像头、车内传感器、视觉识别模块、视觉识别系统、车内信号传输网络、汽车T-BOX、车载电子设备、车联网APP 9个部分。系统工作原理如下:
用户首先在车联网APP内预设个人特定的手势动作要实现的功能,作为手势识别的匹配模板,视觉识别系统将采集的图片进行特征提取、分类,然后通过模板匹配、统计分析技术对图片动作进行解析,并通过神经网络技术不断自学习丰富识别库、提高系统识别用户动作的能力,如打哈欠表示困了、嘘表示安静、双手抱胳膊搓动表示寒冷等常规动作都将在图片系统中不断补充;
车内摄像头实时监控车内乘员,车内摄像头拍摄的视频通过车内传输网络传输到视觉识别模块的视频解码芯片;
车内传感器是红外传感器,用于感应车内的乘员,并将电平信号传输至视觉识别模块;视觉识别模块接收车内传感器信号,并对信号进行解析,结合视频信号进行整合;车内信号传输网络为低压线束,传输的信号是电平信号、CAN信号、CANFD信号、以太网信号;传输的视频信号是LVDS信号、以太网信号。
视觉识别系统将解析后的信息通过车内传输网络发送到汽车-TBOX、车载电子设备和手机APP实现相应的功能。
下面通过车辆具体工作案例说明
首先在车联网APP中预设了部分动作手势:(1) V手势:拍照进行微信朋友圈分享;(2)竖大拇指:对音乐、电台进行收藏;(3)手掌握拳:音乐暂停,手掌张开:音乐继续播放;(4)竖食指放嘴下嘘:静音。
当驾驶员进入车内,车辆处于ACC档/ON档/STAR档,车身控制模块被唤醒,同时车身控制模块唤醒整车网络。
车内摄像头开始按照工作模式开始工作。并通过LVDS信号或以太网信号将视频、图片信号传输到视觉识别模块;
车内红外传感器,感应车内的乘员,并将信号传输至视觉识别模块。
当用户用V手势、竖大拇指灯动作进行交互时,视觉识别模块采集动作视频后,视觉识别系统首先将采集的图片进行特征提取、分类,然后通过模板匹配、统计分析技术对图片动作进行解析,并通过神经网络自学习不断丰富识别库,不断提高可识别内容。
视觉识别系统将识别到的信息转化为CAN信号、CANFD信号传输到汽车T-BOX,汽车T-BOX根据解析的信息,传输到车载电子设备,控制其开关动作。
当需要手机APP交互的,汽车-TBOX接受到视觉识别系统的信息后,通过共享WIFI或网络连接到手机APP(如V手势进行拍照朋友圈分享)。
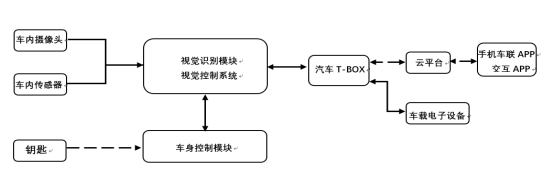
图2视觉手势识别的人-车交互系统结构
此外视觉识别人-车交互系统实现的场景可包括:人脸识别、疲劳监测、分心监测、视线交互,行为识别、后排遗留物体识别、儿童模式、遗留儿童物品检测等的监控。
人脸识别:身份认证、个性化设置等,进而实现如下场景如上车问候:每天首次上车,可根据识别到的性别、年龄等进行语音问候,如:主人,早上好。新的一天,加油哦!
疲劳驾驶监测:通过打哈欠、眼睛睁闭时间判断驾驶员疲劳状态并发出提醒,可分为
轻度疲劳----TTS 提醒:发起语音交互,如“小哥哥,你是困了吗,跟我一起动动脖子,做个深呼吸吧”
中度疲劳----模拟来电:调用正常来电话界面,模拟来电话情况,用户点击接听或挂断会发起语音交互解释。
重度疲劳----提神模式:发起语音交互“即将为您开启提神模式”,若用户未点击取消提神模式,就会进行车窗、空调调节以及播放音乐,来提醒用户。
此外监测到司机疲劳时都会进行服务区提醒:有导航路线时,发现前方有服务区,发起语音交互提醒去服务区休息。
分心提醒:视线长时间未正视车辆前方时,提醒驾驶员专心驾驶。分心提醒还包括以下的提醒
高速路口分心提醒:在导航高速出口时,会检测驾驶员注意力情况,若驾驶员没有看中控导航并且也没看右后视镜区域,并且驾驶员没有打转向灯、未进行明显的减速,则通过车机进行声音报警和动效报警,同时车机转向信息放大闪烁显示提醒;
主驾接听电话分心提醒:检测到驾驶员拿起手机接打电话,发起语音交互,提醒驾驶员不要打电话,专心开车。
抽烟检测:检测到驾驶员或副驾抽烟,如空调处于开启状态,则打开外循环,同时将对应一侧车窗打开。
视线交互:通过视线方向与语音指令多模控制,例如视线位于空调出风口去可直接语音去控制空调开关,视线位于车窗时可直接语音控制车窗。
视线亮屏:车机夜晚状态下,注视车机即可提高屏幕亮度;车机熄屏状态下注视车机可
点亮屏幕。
行为识别:如拍照提示,结合头部位置定位、人脸识别到用户的年龄、性别情绪等,给与用户乐趣性的拍照提示。
此外后排摄像头视觉识别通过动作、人像识别可实现儿童模式,包括如下情景:
儿童上车问候:儿童上车即播放儿童相关内容;
哭闹检测:当儿童哭闹时,播放安抚音乐,及语音交互安慰;
睡眠检测:当检测到儿童睡眠时主动降低音乐音量;
安全带未系提醒:后排儿童未系安全带提醒;
遗留物体儿童检测;识别车内儿童,下车时主动提醒用户,以免儿童、物品遗落;
基于视觉动作识别人-机交互系统的发展将极大丰富车辆中的人-车机交互形态,未来的交互将会是多模态的,多模人机交互也将赋予汽车情感与智慧,让汽车更有智慧,让汽车更懂你,体现未来汽车的人文关怀与感情交流。
参考文献:AI视觉识别 作 者 : 黎清万;钟嘉宝 刊 名 : 中国信息技术教育
出版日期 : 2022 期 号 : 第4期 ISSN : 1674-2117
作者简介 : 黄炜,广西梧州人,本科,中级工程师,研究方向为智能网联、视觉识别

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网 琼ICP备2021005105号



