朱智强
中核核电运行管理有限公司。浙江省,嘉兴市 314300
摘要: 随着信息技术的极速发展,传统的搜索方式已不能满足当前用户的需求,借助大数据技术、自然语言处理等技术,开展特定场景的智能问答研究。本文重点介绍了基于核电领域语义库、核电领域问题集训练构建核电领域智能问答模型,实现物资知识智能问答检索,
关键词: 语义库 智能问答 核电物资
引言
智能问答系统[1]是信息检索系统一种更为高级的形式,它结合了自然语言处理的相关理论,使得用户输入的问句可以是自然语言的形式,并对其进行解答。相比传统搜索引擎,智能问答系统主要有以下两个优点:首先,用户可以用自然语言的方式进行提问,从而可以更精确地表达出真正的搜索需求;其次,智能问答系统返还给用户的检索结果可以直接解答用户输入的问句,而用户不需要自己再去筛选结果,这可以很大程度的减少用户精力和时间的消耗。
随着秦山核电信息化的不断推进和企业内部管理的不断提升,物资管理的数据分散在各个应用系统中。设备工程师等业务人员在物资数据查找、物资数据维护时,面临多个信息系统、页面,以及不同模块之间的数据有断点等问题,主要如下:BOM数据、工单物资申请等数据在EAM系统中,而物资主数据、物资采购、库存数据等在ERP系统中,各个系统没有完全实现数据贯通;物资相关的数据页面是独立分散的,查找一个物资的相关数据或发起相关业务申请,需要在多个页面操作,操作效率低。
语义构建
智能问答中十分重要的一个环节就是问题理解。用户意图是一个抽象的概念,要想做为答案检索的依据,需要把它转换成机器可以理解的形式。对用户问题先做分词处理,中文分词的含义是指将一串汉字序列通过一定的规则切分为一个个单独的词语。目前分词算法主要可以分为三类:基于字符串匹配的分词算法、基于理解的分词算法、基于统计的分词算法[2]。本文使用的是基于词典的分词算法。
对于核电领域内文本的分词,要求分词工具或者词典能够准确捕捉和识别该领域的表达术语词汇。传统的词典在对领域文本处理上具有一定的局限性,领域词典的出现在一定程度上满足了这个要求,它是特定领域特有的术语和表达方式的集合,包含了这一领域内的信息,概念等元素。其中的元素都是从相关的语料中抽取提炼,能够反应某个具体领域特征的术语或词汇,领域词典方便行业内信息的集成和共享。
3.1.词典设计
核电领域词典分为领域专用词词典和领域编码映射/同义词词典,各类词典都以txt文件格式,或者可等价转换为txt格式存储。文件使用UTF-8编码、标准换行符、以及空格分隔符。领域专业用词词典结构为每词一行,每行三列,包含词语、词频、词性,见下图所示, 词频为词语在收集预料中出现的频率,可省略;词性为对词语的分类,分类方法如下文所述;领域同义词字典格式为每组同义词一行,使用“||”为分隔符,如“低压||低电压”。

图1 领域专用词典构建示例
词性是应用于语言和问句法规学科中的字词分类方法,一直以来,无论是汉语还是其他语言,每个词都有自己的词性,如:名词、动词、形容词等。现代汉语里,词汇可以分为12类。实词:名词、动词、形容词、数词、量词和代词;虚词:副词、介词、连词、助词、拟声词和叹词。对于不同的词性,我们用不同的符号进行标记,如表1所示。
表1. 词性编码对照表
词性 | 名词 | 动词 | 形容词 | 副词 | 介词 | 数量词 | 助词 | 连词 | 时间词 |
标记 | n | v | a | d | p | q | u | c | t |
其次,我们需要对不同类别进行进一步标记,使得概念之间区分更加细致,我们以名词的xx类别为例进行标记,以多位字符存储其语义码,第一位确定它的基本词性,以‘n’开头,后面几位用以区别类别,如表2所示,例如:名词“秦三厂”,我们定义其语义码为“nt”, 对照规则表可以看出它是一个机构团体名称的名词。同样,对于动词和形容词也可以按照此方法进行映射编码,这样可以了解到词语的语义信息。
表2. 词性标注符对照表
语义码 | 词类 | |
名词 | nr | 人名 |
nr1 | 汉语姓氏 | |
nr2 | 汉语名字 | |
nrf | 音译人名 | |
ns | 地名 | |
nsf | 音译地名 | |
nt | 机构团体名 | |
nz | 其它专名 | |
nl | 名词性惯用语 | |
ng | 单字名词 |
3.2.词典构建
本文中用来提取领域词汇的语料有结构化数据中的字段,如物料名称、设备名称等;也有文本数据,如物料名称同义词词典中物料名称的同义词则来自对文本数据中物料名称的提取。
对于结构化的数据,则直接将字段中词汇整理、导入txt词典文件。对于文本数据,则采用条件随机场(CRF)模型[3],自动识别文本中相关的领域词汇。CRF是一种典型的判别式模型,既拥有判别式模型的优点,又兼有生成式模型考虑生成标签的转移特征的特性,因此在对命名实体识别中得到广泛应用,也极为适合本文中对文本中物料名称,或制造商名称识别。通过使用通用分词工具(结巴分词)对200份文本做分词、词性标注处理后,再对其中的物料名称做人工标注,采用BIEO标注模式,文本中的每一个词及相应的标注即为一行。以输入单词本身及其词性以及上下文单词及其词性为多种特征组合输入CRF模型,其实体识别的准确率可达92%。
构建的领域词典如表3所示
表3. 构建领域词典列表
类型 | 词典名称 | 数量/(条) |
领域专有词词典 | 设备名称词典 | 458672 |
工单关联文档文档标题词典 | 13873 | |
员工姓名词典 | 66243 | |
机构名称词典 | 612 | |
物料名称词典 | 200819 | |
领域名称编码映射词典 | 设备名称编码映射词典 | 94534 |
专业名称编码映射词典 | 39 | |
系统名称编码映射词典 | 1656 | |
物料名称编码映射词典 | 663209 | |
领域中英文映射 | 中英文映射词典 | 20856 |
领域同义词词典 | 物料名称同义词词典 | 54 |
制造商名称同义词词典 | 174 |
问答系统构建
智能问答主要通过以下几个步骤完成从用户问题输入到机器答案输出的:
1)首先用户通过自然语言形式描述自己的提问
2)机器把用户输入的问句转换成机器能理解的文本形式
3)将文本通过模型解析,匹配到知识库中相似度最高的标准问句
4)最后把答案输出,展现给用户
依据数据流在问答系统中的处理流程, 问答系统的处理框架中包括问句理解、信息检索、答案生成三个功能组成部分。
3.1.问句理解
问句理解是问答系统理解用户意图的关键一环,用户意图是一个抽象的概念,要想做为答案检索的依据,需要把它转换成机器可以理解的形式。问句理解主要指问句分类、关键字提取、问题扩展处理。文句分类时已经完成关键字提取,通过问句中关键字判断问句所属类型。
3.1.1.问句分类
使用机器学习中的随机森林算法训练问题分类器来实现用户提问的分类。模型训练过程如图2所示。

图2. 问句分类模型训练流程图
1)问题类别标签创建
智能问答涉及的数据对象有物料、人员、设备、制造商、BOM、工单任务、物资申请(MR)、质量缺陷报告(QDR)、变更、工作项、工单的备件消耗、预防性维修(PM)项目、采购订单、领料单、物料凭证、供应商、物资库存、物资库存保养。
对问卷调查中收集的一些问题样本,格式化整理并创建类别标签,最终将问题分为九个类别,分别为重码查询类、物料库存类、采购申请类、路径类、设备类、工单类、BOM类、制造商类、领料单类、备件类。
问题类别标签创建是通过0-8的9个数字对样本问题做分类标记,不同数字表示不同类型的问题,用做分类模型训练时样本数据的目标变量。详见表4.
表4 问题类别标签
问题类别 | 问题描述 | 代表问句 |
0 | 重码查询类 | xxx编码的物料与xxx编码的物料是否重码 |
1 | 物料库存类 | xxx编码物料的库存数量 |
2 | 采购申请类 | xxx编码物料的采购数量 |
3 | 路径类 | xxx编码的设备使用的xxx编码的物料数量 |
4 | 设备类 | 使用xxx编码物料的设备数量 |
5 | 工单类 | xxx位置的历史使用备件情况 |
6 | BOM类 | 使用xxx编码物料的BOM数量 |
7 | 制造商类 | xxx编码物料的制造商名称 |
8 | 领料单类 | xxx编码物料被哪些领料单使用 |
9 | 备件类 | xxx位置的历史使用备件情况 |
2)问题文本预处理
问题文本预处理指借助通用词典、核电领域专业词典对问题文本进行分词、词性标注;如问句“111109001256设备编码的历史使用备件情况”分词处理的结果如下:
分词结果:111109001256 设备 编码 的 历史 使用 备件 情况
词性标注结果: mmdvn n uj n v n n
把问题样本中提到的词都保存到问题词汇表中,如图3所示,并且按照词汇索引升序排列,这样问题中出现的词都可在词汇表中找到对应索引,如问句“5842180005编码的物料的库存数量”中“数量”对应的索引为28。

图3. 词汇表示例
3)问题表示
使用词袋模型(Bag of Words)对分词后的问题向量化表示。在分词之后,通过统计每个词在问句文本中出现的次数,即可得到该文本基于词的特征。将各个问句样本的这些词与对应的词频放在一起,即完成问句向量化。向量化完毕后一般也会使用TF-IDF进行特征的权重修正,再将特征进行标准化,就可以将数据带入机器学习算法进行模型训练了。词袋模型的局限性是它仅仅考虑了词频,没有考虑上下文的关系,因此会丢失一部分文本的语义。但是本文中,我们的目的是对问句文本分类,则词袋模型表现能很好地满足这一需求。
问句“111109001256设备编码的历史使用备件情况”分词后,用词袋模型做问题的特征向量化,把问题的分词结果与词汇表中的词做特征匹配,对出现的词表示为1,否则为0,结果为:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0]
4)模型训练
使用随机森林模型做为问句分类器。随机森林是以决策树为基础的一种更高级的算法。像决策树一样,随机森林即可以用于回归也可以用于分类。从名字中可以看出,随机森林是用随机的方式构建的一个森林,而这个森林是由很多的相互不关联的决策树组成。实时上随机森林从本质上属于机器学习的一个很重要的分支叫做集成学习。集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
训练模型时,先将样本数据按9:1的比例分为训练数据与测试数据,采用5折交叉验证方法训练模型。训练集的混淆矩阵如图4所示。测试数据的混淆矩阵如图5所示,结果显示,9类问题的召回率和准确率都为100%,模型的泛化性能非常理想。

图4. 训练集混淆矩阵结果
图5. 测试集的混淆矩阵
3.1.2.问题扩展
问题扩展是智能问答系统中非常重要的一个步骤,在提取问句的关键词之后,需要基于关键词进行答案搜索,但是由于中文语言的特点,答案中的词语可能不是原来问题中的关键词,这样就可能错过正确的答案,导致检索失败。因此需要对关键词进行一定的扩展。关键词的扩展方式主要有两种,一种是基于同义词进行扩展,在同义词词典中查询与关键词同义的词语,将关键词的同义词扩展到查询中;一种是基于问题类型进行扩展。本文使用的是基于同义词词典对问题进行扩展。
3.2.信息检索
根据问句理解得到的查询表示,信息检索模块负责从知识库中检索相关信息,专递给后续的答案生成处理模块。对于基于不同的问答系统,系统的检索模型以及检索数据形式也不同。本文是基于知识图谱、以及Mysql数据库的问答系统,信息检索处理是根据分类器确定的问题类别,到数据库中查询预先写入的该类问题的cypher或者Sql查询语句,进行语句中参数值与实际值进行替换,并在知识图谱或数据库中搜索该问题的答案。过程如图6所示:

图6 问句答案检索流程
3.3.答案生成
智能问答系统返回的答案包含两个部分:自然语言形式的总体回答,以及表格形式的答案数据细节展示,见图7。每类问题拥有一个对应的答案模版,将在知识图谱或Mysql数据库中查询的答案数据填入答案模版,即可生成答案。
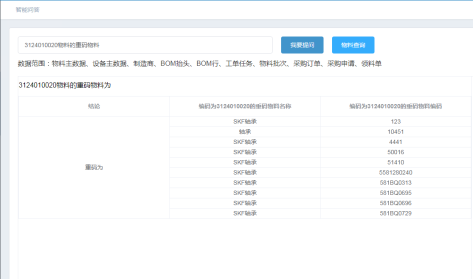
图7 智能问答答案示例
结束语
基于核电领域语义库、核电领域问题集训练构建核电领域智能问答模型,实现物资知识智能问答检索,满足了当前用户的智能搜索的需求。应用支持通过自然语言的方式进行提问;能够提供用户全面、准确的检索结果;能够适应多变的信息检索,满足业务人员在业务场景中常用的检索需求;能够收集用户在使用过程中检索问题并存储到数据库中,可用于后续功能的延展和升级。
但是基于当前特定场景的智能问答,需要进一步进行扩充来满足多种对话场景的应用。同时智能问答,需要在在现有语义库的基础上,扩展语义库的数据范围,提供数据可视化操作,提升智能问答平台问句分析能力,实现更加全面的问题体系,面向更多的业务场景和业务人员。
参考文献
【1】周俊生,戴新宇,尹存燕,陈家骏 基于层叠条件随机场模型的中文机构名自动识别 电子学报 2006(05)
【2】余战秋巢湖广播电视大学中文分词技术及其应用初探电脑知识与技术(IT认证考试)2004, (11)
【3】孙晓,孙重远,任福继 基于深层条件随机场的生物医学命名实体识别模式识别与人工智能 2016, 29(11)
【4】许保勋 面向高维数据的随机森林算法优化研究

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网 琼ICP备2021005105号



